Exploring Retrieval Augmented Generation (RAG) with Vector Databases and AI Agents
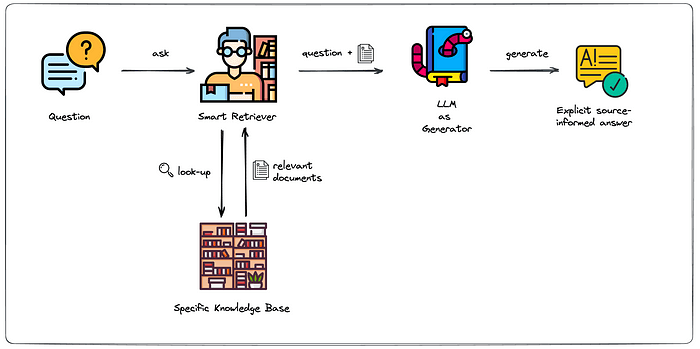
One of the recent breakthroughs is Retrieval Augmented Generation (RAG). This concept blends the power of generative models with external retrieval systems to enhance the quality and accuracy of responses. When coupled with vector databases and AI agents, RAG creates a highly dynamic and intelligent system capable of delivering more contextually relevant and fact-based outputs. In this blog, we will dive into how RAG works, the role of vector databases, and how AI agents enhance this process.
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) is an approach where a generative model doesn't rely solely on its learned parameters but instead enhances its output by retrieving information from a large corpus of data. The retrieval process ensures that the AI system has access to the most up-to-date and accurate information during its response generation.
Traditional models often struggle with answering questions that require factual knowledge not seen during training, leading to hallucinations or incorrect answers. RAG improves upon this by using an external database to retrieve relevant information and passing that information to the generative model for more context-aware and grounded responses.
How Does RAG Work?
Query Input: A user inputs a query, much like any other question or request posed to a system.
Retrieval: The system first searches an external source of knowledge (like a vector database) for documents, texts, or passages related to the query.
Document Ranking: Using techniques like semantic search or nearest neighbor search, relevant documents are ranked and selected based on how similar they are to the query.
Generation: The retrieved documents are then passed as context to a generative model, like GPT-3 or GPT-4. This model uses the retrieved information along with its internal knowledge to generate a well-informed, accurate response.
Response Output: The generative model creates a response that incorporates the retrieved information, ensuring it is grounded in facts and highly relevant to the user's query.
The Role of Vector Databases in RAG
Vector databases play a critical role in the retrieval process of RAG. These databases store embeddings (dense vector representations) of large datasets, which makes it easy to perform efficient similarity searches.
When a query is inputted, it is transformed into a vector through a process known as embedding. This vector is then compared against the vectors stored in the database to find the most relevant documents. Vector databases are optimized for this task, offering high-performance similarity search capabilities. Some popular vector databases include:
FAISS (Facebook AI Similarity Search): An open-source library that allows fast similarity search in high-dimensional spaces.
Pinecone: A managed vector database service that offers scalable similarity search.
Weaviate: An open-source vector search engine that can integrate with various machine learning models.
These vector databases help ensure that RAG can retrieve the most relevant documents in real-time, even from massive data corpora.
Vector Representation of Texts
To efficiently perform search, text data (such as documents, articles, or websites) must be converted into vectors. This is done using embedding models like Sentence-BERT or OpenAI’s embedding models. These models convert each piece of text into a vector of fixed dimensionality, which can then be indexed by the vector database. Similarity measures such as cosine similarity or Euclidean distance are used to rank the retrieved documents.
A Practical Example of RAG with Vector Databases and AI Agents
Let’s consider an example of a chatbot built using RAG with a vector database and AI agent:
Scenario: An AI-powered Virtual Assistant for Technical Support
Imagine you are building a virtual assistant for technical support in a software company. Users will ask questions about the software’s features, installation guides, troubleshooting steps, etc.
Here’s how RAG can be used:
User Query: "How do I install the software on Linux?"
AI Agent: The AI agent processes the query, recognizes that the user is asking about software installation on a Linux system, and formulates a precise query for the vector database: "Linux installation guide for software."
Retrieval: The vector database retrieves relevant documents, such as installation guides, forums, or knowledge base articles related to Linux installations.
Generation: The generative model takes these documents and crafts a coherent, step-by-step installation guide tailored to the user’s query.
Response: The AI agent outputs: "To install the software on Linux, follow these steps... [steps from the retrieved guide]"
The AI agent ensures the process is seamless and context-aware, making it easy for the user to get accurate and relevant answers without needing to sift through long documentation.
Implementation
To implement the example you described using LangChain and a vector database, you can follow the steps outlined below. We will break down the process into key components:
Setting up the vector database to store and retrieve relevant documents.
Integrating LangChain to connect the vector database with a language model for retrieval-augmented generation (RAG).
Building the AI Agent that processes the user query, retrieves relevant data, and generates a response.
Step 1: Setup Vector Database
We will use FAISS (Facebook AI Similarity Search) or Pinecone as the vector database to store document embeddings. First, we need to create embeddings for your documents and store them in the database.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
import faiss
import os
# Initialize OpenAI embeddings model (or any other model)
embeddings = OpenAIEmbeddings()
# Initialize the vector store (FAISS in this case)
faiss_index = FAISS.load_local("path/to/faiss_index") # Load or create your FAISS index
# Assuming documents are available as a list of strings
documents = [
"Linux installation guide for software...",
"How to troubleshoot software on Linux...",
"Windows installation steps for software...",
# more documents here
]
# Create embeddings for documents
doc_embeddings = embeddings.embed_documents(documents)
# Store documents in the FAISS index
faiss_index.add(np.array(doc_embeddings).astype(np.float32)) # FAISS index requires float32 embeddings
Step 2: Retrieval-augmented Generation (RAG) Setup
Now we integrate LangChain to allow the agent to retrieve relevant documents from the vector database and generate responses based on that.
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.agents import initialize_agent
from langchain.agents import Tool
# Create a retrieval chain
retriever = faiss_index.as_retriever(search_kwargs={"k": 3}) # Retrieve top 3 results
# Use OpenAI or any other LLM for generation
llm = OpenAI(temperature=0.7)
# Create a RetrievalQA chain (combines retrieval and generation)
qa_chain = RetrievalQA(combine_docs_chain=llm, retriever=retriever)
# Define the tools for the agent (including QA system)
tools = [
Tool(
name="Technical Support Assistant",
func=qa_chain.run,
description="Retrieve technical support documents from the knowledge base."
)
]
# Initialize the agent with the tools and an LLM
agent = initialize_agent(tools, llm, agent_type="zero-shot-react-description", verbose=True)
Step 3: Implement the AI Agent for User Queries
The agent will now be capable of handling user queries related to technical support. When a user asks, for example, "How do I install the software on Linux?", the agent will retrieve relevant documents and generate a response.
# Simulating user query
user_query = "How do I install the software on Linux?"
# Pass the query to the agent for processing
response = agent.run(user_query)
# Display the AI's response
print(response)
Final Workflow
User submits a query: "How do I install the software on Linux?"
Vector database retrieves relevant documents based on query embeddings.
LangChain agent processes the retrieved documents and passes them to the generative model (OpenAI, or any other model you're using).
AI agent generates a response combining retrieved documents in a coherent way, such as a step-by-step guide on how to install the software on Linux.
Additional Notes:
You can store documents as embeddings in your vector database using various models, including OpenAI, SentenceTransformers, or other pre-trained models.
Ensure the knowledge base is regularly updated to maintain accuracy and relevance.
The agent can be enhanced with more advanced features like error handling, multi-step reasoning, or including additional tools for different types of queries.