Guide to Choosing the Right Database for Your App
Selecting the appropriate data store for your application is crucial. Here’s an overview of database types and when to choose each for specific use cases:
Relational Databases (RDBMS)
Characteristics:
Organize data into tables with predefined schemas.
Support strong ACID (Atomicity, Consistency, Isolation, Durability) properties.
Use SQL for querying.
Best for applications needing complex queries, transactions, and structured data.
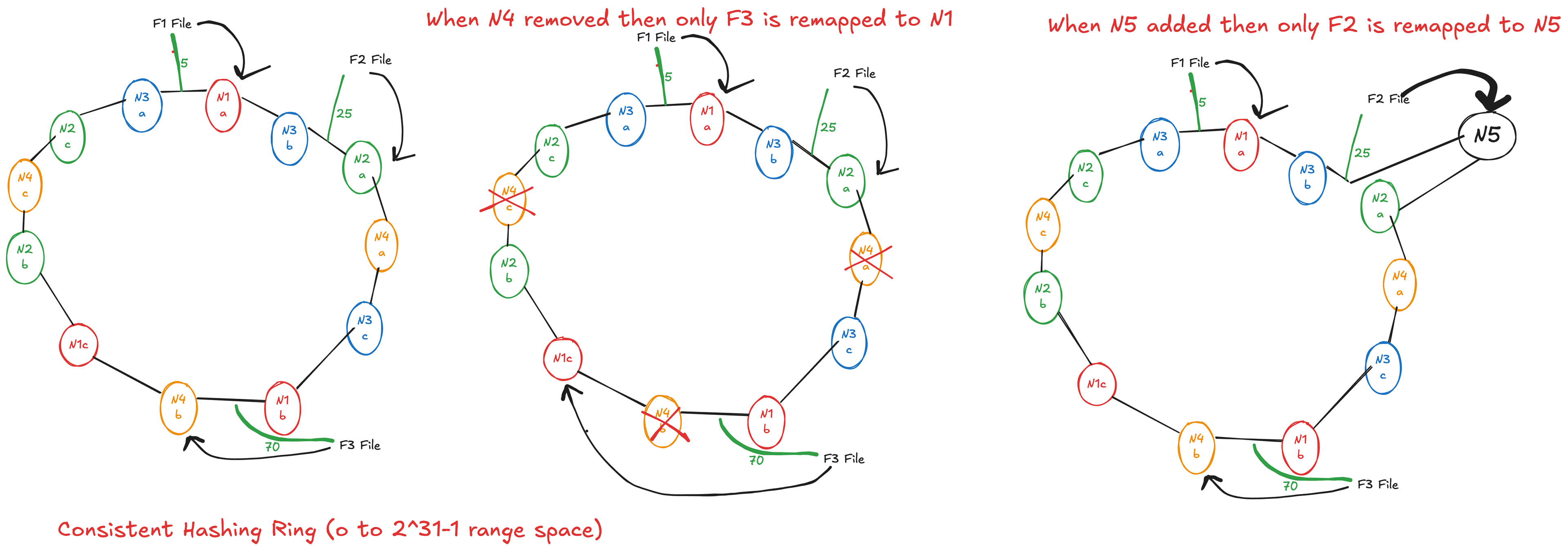
Sharding is possible in it but not well supported (no built in )
- SQl guarantee consistency but wait all shard to agree on transaction can be costly.
Databases:
- Microsoft SQL Server, PostgreSQL, MySQL, Oracle Database.
When to Choose:
Applications with structured data
Applications with fixed/strict schemas.
Scenarios needing complex relationships between entities (e.g., e-commerce, banking) or complex joins.
Use cases requiring strict consistency and ACID transaction support.
Examples
Inventory/Order/Reporting management
Accounting/ Banking
NoSQL Databases
When to Choose:
Applications with Semi-Structure data
Applications with Dynamic schema
Not much need of complex joins
Store many TB's of data and highly scalable
Key-Value Stores
Characteristics:
Simplest type of NoSQL database.
Data is stored as key-value pairs.
Optimized for fast reads and writes.
Databases:
- Redis, DynamoDB.
When to Choose:
Data is accessed using a single key, like a dictionary.
No joins, lock, or unions are required.
No aggregation mechanisms are used.
Quick lookup and relationship are minimal.
Example:
- Caching, session management, and real-time analytics.
Document Databases
Characteristics:
Store semi-structured data as JSON or BSON documents.
Allow flexible schemas and hierarchical data.
Databases:
- MongoDB, Dynamodb, cosmosDB
When to Choose:
Flexible Schemas are required and index varies required on multiple fields
Scenarios where data structure varies across records.
Example:
- Content management systems, product catalogs, or applications needing flexible schemas.
Column-Family Stores
Characteristics:
Data is stored in tables but optimized for columnar storage instead of rows. Each column is a part of column family.
Scalable and efficient for write-heavy workloads.
Update and delete operations are rare.
Designed to provide high throughput and low-latency access
Databases:
- Cassandra, HBase, ScyllaDB.
When to Choose:
Heavy write operations
High throughput and low latency
Example:
- Recommendations, Personalization, Sensor data, Telemetry, Messaging, Social media analytics, Activity monitoring, Weather and other time-series data
Graph Databases
Characteristics:
Represent data as nodes and edges, ideal for modeling relationships.
Use graph-based querying languages like Gremlin or Cypher.
Examples:
- Neo4j, Cosmos DB (Gremlin API), Amazon Neptune.
When to Choose:
Social networks, recommendation engines, fraud detection.
Use cases where relationships are critical and highly interconnected.
Time-Series Databases
Characteristics:
Designed to handle time-stamped or sequential data.
Optimized for time-series analysis and aggregation.
Examples:
- InfluxDB, TimescaleDB, OpenTSDB.
When to Choose:
- IoT sensor data, financial transactions, performance monitoring.
Search Databases
Characteristics:
Optimized for full-text search and analysis.
Provide advanced query and indexing capabilities for text.
Examples:
- Elasticsearch, Solr, Azure Cognitive Search.
When to Choose:
Applications needing text search or log analysis.
Use cases like e-commerce product search or log monitoring.
Object Storage
Characteristics:
Designed for storing large, unstructured data (files, images, videos).
Offers flat namespaces and metadata for objects.
Examples:
- Amazon S3, Azure Blob Storage.
When to Choose:
- Media storage, backups, archival, or big data pipelines.
In-Memory Databases
Characteristics:
Data is stored in memory for ultra-fast access.
Often used as caching layers.
Examples:
- Redis, Memcached.
When to Choose:
- Real-time analytics, session stores, or scenarios requiring low-latency data access.
Choosing the Right Database
Workload Type:
OLTP (Online Transaction Processing): Relational or document databases.
OLAP (Online Analytical Processing): Column-family or time-series databases.
Data Relationships:
Strong relationships: Relational or graph databases.
Weak or no relationships: NoSQL (key-value, document).
Scalability:
Horizontal scalability: NoSQL databases.
Vertical scalability: Relational databases.
Consistency vs. Availability:
Strict consistency: Relational databases.
Eventual consistency: NoSQL databases.
Schema Flexibility:
Fixed schema: Relational databases.
Flexible schema: Document or key-value stores.
Querying Needs:
Complex queries: Relational or graph databases.
Simple queries: Key-value or column-family stores.
By analyzing your use case across these dimensions, you can confidently choose the database that best fits your requirements.
Which one to choose when
Check if ACID is required then sql, otherwise nosql.
- Replication and sharding can be achieved in both. Sharding is bit difficult to achieve in SQL because no built in support.
High availability and compromise with consistency then nosql
Consider below factor while choosing databases:
- Have Structured data ? , Need complex Joins ?, Need Transaction , Consistency level, Need high Scalability ? (SJTCS)
References:
https://learn.microsoft.com/en-us/azure/architecture/guide/technology-choices/data-store-overview