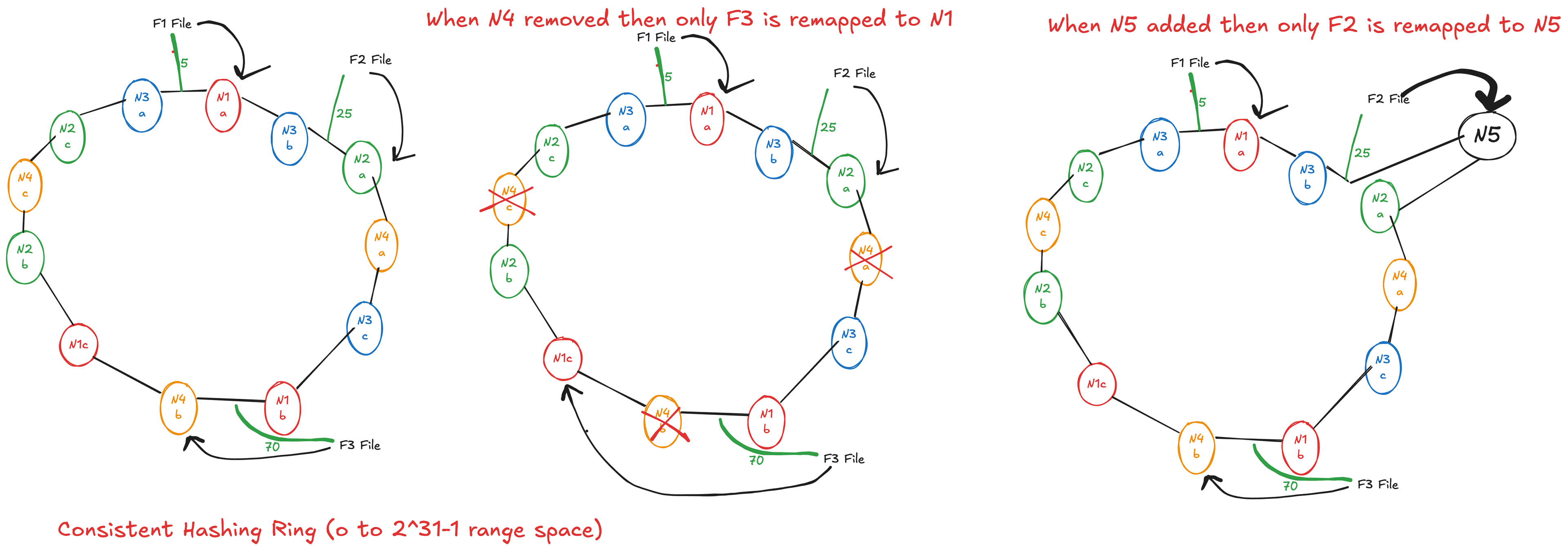
Navigating System Design: How Scalability, Reliability, Availability, and Performance Shape Success
When designing modern distributed systems, four key attributes stand out as pillars of success: Scalability, Reliability, Availability, and Performance. Together, these "Fantastic Four" guide architects and engineers to build robust systems capable of meeting diverse and demanding requirements. Let’s explore each of these in detail
1. Scalability: Designing for Growth
Scalability refers to a system's ability to handle increased load by adding resources, either horizontally (more machines) or vertically (better machines). A well-scalable system does not degrade performance.
Few Key Considerations for scalability:
Load Balancing: Distributing requests across multiple servers to avoid bottlenecks.
Stateless Services: Stateless design enables easier scaling as each request can be handled independently.
Partitioning/Sharding: Splitting data across different databases or servers.
Example:
Think of an e-commerce platform during a holiday sale. The system must scale to handle millions of requests and transactions simultaneously.
2. Reliability: Building Trust in the System
Reliability ensures that the system performs correctly under expected conditions and gracefully degrades under unexpected conditions. A reliable system minimizes failures and provides consistent results.
Techniques to Enhance Reliability:
Redundancy: Duplicating critical components to avoid single points of failure.
Failover Mechanisms: Automatically switching to backup systems during a failure.
Data Replication: Keeping multiple copies of data across different nodes or regions.
Example:
Payment gateways rely heavily on reliability. Even a minor glitch can lead to financial losses or customer dissatisfaction.
3. Availability: Ensuring Uptime
Availability is about how often a system is operational and accessible. It’s measured by uptime percentages. High availability (HA) systems aim for 99.99% uptime or better.
Strategies to Achieve High Availability:
Load Balancers and Health Checks: Continuously monitor services and route traffic to healthy nodes.
Distributed Systems: Spreading services across multiple data centers ensures availability even during regional outages.
Graceful Degradation: Allowing partial functionality when full service is not possible (e.g., read-only mode for a database).
Example:
Social media platforms prioritize availability to ensure users can access their accounts at any time, across the globe.
4. Performance: Speed and Efficiency
Performance measures how fast and efficiently a system processes requests and delivers results. Poor performance can drive users away, regardless of other attributes.
Key Performance Metrics:
Latency: Time taken to process a request.
Throughput: Number of requests processed per unit time.
Resource Utilization: CPU, memory, and network bandwidth usage.
Performance Optimization Techniques:
Caching: Storing frequently accessed data in memory to reduce response times.
Content Delivery Networks (CDNs): Distributing static content closer to users.
Asynchronous Processing: Handling non-critical tasks in the background.
Example:
Search engines like Google prioritize performance to return search results in milliseconds, enhancing user experience.
Final Thoughts
The "Fantastic Four" of system design—scalability, reliability, availability, and performance—are not just buzzwords but essential principles that drive the architecture of modern systems. Mastering these concepts empowers engineers to build systems that not only meet today’s demands but are also prepared for future challenges.
In your next project, consider these pillars as guiding stars to ensure success in the ever-evolving landscape of distributed systems.